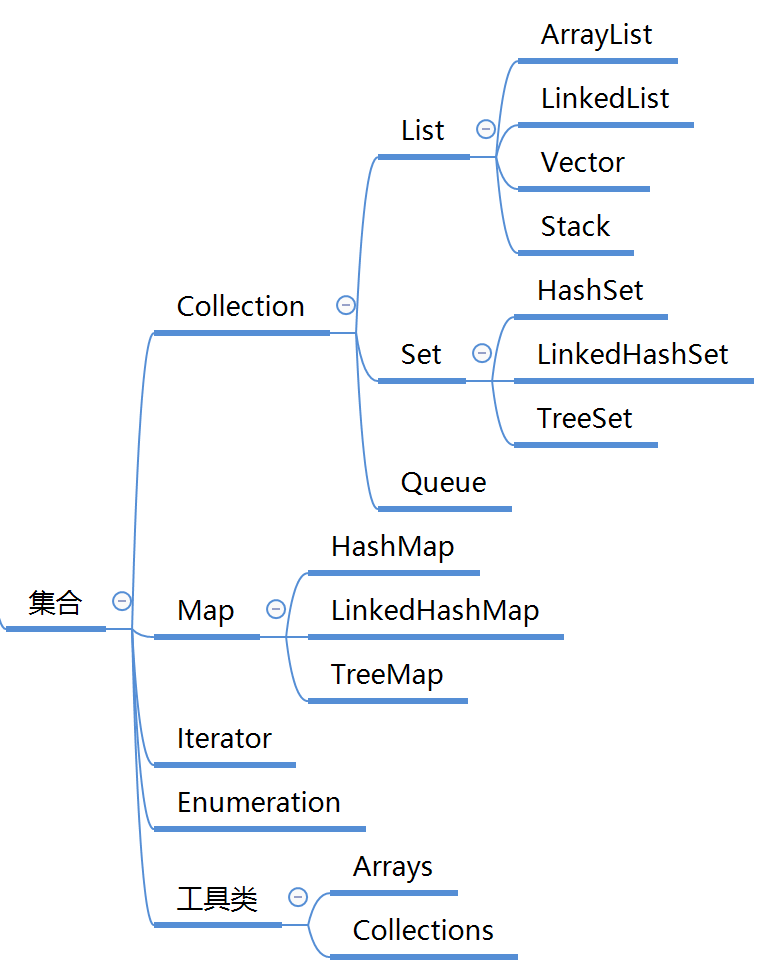
总框架
所有集合类都位于
java.util包下。Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些子接口或实现类
Collection
Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。Collection包含了List和Set两大分支
List
List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。
List 有序,可重复
List的实现类有LinkedList, ArrayList, Vector, Stack。
List接口提供了一个特殊的迭代器,称为ListIterator,其允许元件插入和更换,并且除了该Iterator接口提供正常操作的双向访问。 提供了一种方法来获取从列表中的指定位置开始的列表迭代器。
ArrayList
ArrayList擅长于随机访问。同时ArrayList是非同步的。
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector
Vector是线程安全的动态数组
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
LinkedList
LinkedList不能随机访问,也是非同步的
优点: 底层数据结构是双向链表,查询慢,增删快。
缺点: 线程不安全,效率高
ArrayList-LinkedList-异同点
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
- 对于随机访问get和set,ArrayList绝对优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
1、寻址操作次数链表要多一些。数组只需对 [基地址+元素大小*k] 就能找到第k+1个元素的地址,对其取地址就能获得该元素。链表要获得第k个元素,首先要在其第k-1个元素寻找到其next指针偏移,再将next指针作为地址获得值,这样就要从第一个元素找起,多了多步寻址操作,当数据量大且其它操作较少时,这就有差距了。
该回答源自:http://tieba.baidu.com/p/5069120437
2、CPU缓存会把一片连续的内存空间读入,因为数组结构是连续的内存地址,所以数组全部或者部分元素被连续存在CPU缓存里面,平均读取每个元素的时间只要3个CPU时钟周期。 而链表的节点是分散在堆空间里面的,这时候CPU缓存帮不上忙,只能是去读取内存,平均读取时间需要100个CPU时钟周期。这样算下来,数组访问的速度比链表快33倍! (这里只是介绍概念,具体的数字因CPU而异)。
Set
Set是一个不允许有重复元素的集合,无序,Set最多有一个null元素。
虽然Set中元素没有顺序,但是元素在set中的位置是由该元素的HashCode决定的,其具体位置其实是固定的。
Set的实现类有HashSet和TreeSet,LinkHashSet。HashSet依赖于HashMap,它实际上是通过HashMap实现的;TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。
HashSet
没有重复元素的集合
是由HashMap实现的
不保证元素的顺序
是非同步的
HashSet按Hash算法来存储集合的元素,因此具有很好的存取和查找性能。
LinkedHashSet
底层是基于LinkedHashMap来实现的
有序,非同步。
根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序
当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
TreeSet
一个有序集合,其底层是基于TreeMap实现的,非线程安全
TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式
TreeSet集合不是通过hashcode和equals函数来比较元素的.它是通过compare或者comparaeTo函数来判断元素是否相等.compare函数通过判断两个对象的id,相同的id判断为重复元素,不会被加入到集合中。
HashSet、LinkedHashSet、TreeSet比较
Set接口
Set不允许包含相同的元素,如果试图把两个相同元素加入同一个集合中,add方法返回false。
Set判断两个对象相同不是使用==运算符,而是根据equals方法。也就是说,只要两个对象用equals方法比较返回true,Set就不会接受这两个对象。
HashSet
HashSet有以下特点:
- 不能保证元素的排列顺序,顺序有可能发生变化。
- 不是同步的。
- 集合元素可以是null,但只能放入一个null。
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值也相等。
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
TreeSet类
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0。
Map
Map是一个映射接口,即key-value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。AbstractMap是个抽象类,它实现了Map接口中的大部分API。而HashMap,TreeMap,WeakHashMap都是继承于AbstractMap。Hashtable虽然继承于Dictionary,但它实现了Map接口
不能存在相同的key值,当然value值可以相同。
HashMap
以哈希表数据结构实现,查找对象时通过哈希函数计算其位置,它是为快速查询而设计的,
是一个单链表结构
非线程安全
LinkHashMap
LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序
双重链接列表
非线程安全
由于LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能
但在迭代访问Map里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
TreeMap
TreeMap 是一个有序的key-value集合,非同步,基于红黑树(Red-Black tree)实现,每一个key-value节点作为红黑树的一个节点
排序方式也是分为两种,一种是自然排序,一种是定制排序,具体取决于使用的构造方法
自然排序:TreeMap中所有的key必须实现Comparable接口,并且所有的key都应该是同一个类的对象,否则会报ClassCastException异常。
定制排序:定义TreeMap时,创建一个comparator对象,该对象对所有的treeMap中所有的key值进行排序,采用定制排序的时候不需要TreeMap中所有的key必须实现Comparable接口。
TreeMap判断两个元素相等的标准:两个key通过
compareTo()方法返回0,则认为这两个key相等。
HashTable与HashMap的异同点
相同点:
- 都实现了
Map、Cloneable、java.io.Serializable接口。- 都是存储”键值对(key-value)”的散列表,而且都是采用拉链法实现的。
不同点:
(1)历史原因:HashTable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现 。
(2)同步性:HashTable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的 。
(3)对null值的处理:HashMap的key、value都可为null,HashTable的key、value都不可为null 。
(4)基类不同:HashMap继承于AbstractMap,而Hashtable继承于Dictionary。
(5)支持的遍历种类不同:HashMap只支持Iterator(迭代器)遍历。而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
HashMap、Hashtable、LinkedHashMap和TreeMap比较
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。
Hashtable 与 HashMap类似,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。对于LinkedHashMap而言,它继承与HashMap、底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。
TreeMap实现SortMap接口,内部实现是红黑树。能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
Iterator
它是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。我们说Collection依赖于Iterator,是因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。ListIterator是专门为遍历List而存在的
1 | public interface Iterator<E> { |
操作一下Iterator的这三个方法
1 | public static void Test1() { |
结果为:
Before iterate : [aaa, bbb, ccc]
After iterate : [aaa, ccc]
ListIterator
针对List集合
1 | public static void Test2() { |
结果:
Before iterate : [aaa, bbb, ccc]
it.next() : aaa ,前位置: 0,后位置: 1
it.next() : bbb ,前位置: 1,后位置: 2
it.next() : ccc ,前位置: 2,后位置: 3
it.previous() : ccc
it.previous() : bbb
it.previous() : aaa
t:bbb
t:ccc
After iterate : [aaa, bbb, kkk, nnn]
Enumeration
作用和Iterator一样,也是遍历集合;但是Enumeration的功能要比Iterator少。在上面的框图中,Enumeration只能在Hashtable, Vector, Stack中使用。只提供了遍历Vector和HashTable类型集合元素的功能,不支持元素的移除操作
用法和Iterator类似,该接口有2个方法
1 | boolean hasMoreElements() |
操作Enumeration方法
1 | public static void Test3() { |
结果:
Enumeration前[Lisa, Billy, Mr Brown]
Lisa
Billy
Mr Brown
工具类
Collections
它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,用于对集合中元素进行排序、搜索以及线程安全等各种操作,服务于Java的Collection框架。
小唠嗑:
本章到这里就结束了,谢谢耐心看到这里的各位Boss,如果觉得有哪里说的不好的地方,还请高抬贵手多多原谅,不惜指教。
最后,谢谢!